
| Процессоры | Системные платы | Видеосистема |
| Процессоры | Системные платы | Видеосистема |
В ожидании Willamette - история архитектуры IA-32 и как работают процессоры семейства P6
Совершенно очевидно, что определяющую роль в продвижении продукта на рынок играют далеко не его потребительские качества, а то, как он позиционируется, рекламируется и преподносится потенциальным покупателям. А уж такой уникальный продукт, как Pentium 4, созданный с чистого листа и предоставляющий невиданную доселе производительность всем и каждому, а в особенности поклонникам Internet'а, количество которых растет как на дрожжах, просто обречен на успех. При этом еще не вышедший процессор, как снежный ком, с катастрофической быстротой обрастает неимоверным количеством слухов, всевозможных тестов, причем как положительных, так и не очень, предположений, причем как достаточно правдоподобных, так и совершенно абсурдных. Попробуем разобраться в массе противоречивой информации и дать по возможности максимально развернутое и правдоподобное описание продукта, на который Intel делает ставку в ближайшие два года. В связи с большим количеством материала, имеющего отношение к процессору Pentium 4, решено разделить обзор на несколько малозависимых друг от друга глав, чтобы читатели могли пропустить неинтересные для них разделы и ознакомиться с избранными, не рискуя полностью потерять нить повествования. Как все начиналось - история развития архитектуры IA-32Никто не станет спорить, что архитектура Intel Architecture стала стандартом "де-факто" современной компьютерной индустрии. Основополагающими факторами такой популярности Intel считает полную совместимость программного обеспечения, разработанного под Intel Architecture процессоры, и все более серьезные увеличения производительности, предлагавшиеся с выходом новых поколений процессоров. Проследим путь компании от истоков - 16-разрядной архитектуры, до современной 32-разрядной архитектуры IA-32 , применяющейся во всех современных процессорах от Intel. Родоначальниками процессорной архитектуры Intel Architecture являлись 16-разрядные процессоры 8088 и 8086, причем объектный код, разработанный в расчете на них в 1978 году, и поныне без проблем исполняется на самых последних процессорах архитектуры IA-32. Процессор 8086 имел 16-разрядные регистры общего назначения, 16-разрядную шину данных и 20-разрядную шину адреса, что позволяло ему оперировать адресным пространством в 1 мегабайт. Отличие процессора 8088 заключалось в 8-разрядной шине данных. Эти процессоры привнесли сегментацию в архитектуру IA-32. Память разделялась на сегменты размером до 64 килобайт. Оперируя четырьмя сегментными регистрами одновременно, процессор имел возможность адресации до 256 килобайт памяти без переключения между сегментами. При этом 20-разрядные адреса получались путем добавления 16-разрядного адреса к указателю сегментного регистра. Процессор 80286 привнес в архитектуру IA-32 защищенный режим. В нем содержимое сегментных регистров используется в качестве указателей на таблицы дескрипторов, которые давали возможность 24-разрядной адресации, что составляло 16 мегабайт адресного пространства. К тому же, появилась возможность проверки границ сегментов, опций read и execute-only для сегментов и 4 уровня защиты кода операционной системы от приложений и защита приложений друг от друга. Intel 80386 стал первым 32-разрядным процессором в архитектуре IA-32. В архитектуру введены 32-разрядные регистры общего назначения (GP - general purpose), подходящие как для хранения адресов, так и для операндов. Нижняя и верхняя половина сохранили возможность работы в качестве самостоятельных регистров для обеспечения совместимости с предыдущими процессорами. Для обеспечения эффективного выполнения кода, созданного под ранние процессоры, на 32-разрядных процессорах, был введен виртуальный х86 режим. Имея 32-разрядную шину адреса, 80386 процессор поддерживал адресацию до 4 гигабайт памяти. При этом была возможность использования как сегментированной памяти, так и "плоской", при которой все сегментные регистры содержали указатель на один и тот же адрес, и в каждом сегменте доступно все 4-х гигабайтное адресное пространство. Для виртуального управления памятью вводится страничный метод, при котором адресное пространство делится на фиксированные страницы размером по 4 килобайта, эффективность которого значительно превышала использование сегментов. 16-разрядные инструкции, доставшиеся в наследство от предыдущих процессоров, получили возможность работы с 32-разрядными операндами и адресами, а также был добавлен ряд новых 32-разрядных инструкций. В поисках новых технологий для увеличения быстродействия, в 80386 впервые реализована возможность параллельной работы нескольких блоков процессора, что положило начало конвейеризации вычислений в процессоре 80486. В новом процессоре 80486 блок декодирования команд и блок вычислений преобразованы в пяти-стадийный конвейер, в котором каждая стадия по мере надобности могла выполняться параллельно с другими, исполняя до 5 команд на разных стадиях выполнения. Конвейерные микропроцессоры выполняют команды подобно сборочной линии: полная обработка каждой инструкции занимает несколько тактов, но, разбивая процесс на несколько этапов, и начиная выполнение следующей команды сразу вслед за тем, как предыдущая команда пройдет первый этап, можно быстро выдать несколько завершенных команд. При этом нельзя не отметить и такие технологические инновации, как 8-килобайтный кэш первого уровня в чипе для обеспечения полноценной загрузки конвейера, интегрированный х87 сопроцессор, а также расширения для поддержки внешнего кэша 2-го уровня и многопроцессорных систем. Процессор Pentium стал первым процессором, в котором была применена суперскалярная архитектура - два конвейера, называвшиеся U и V, позволяли выполнять 2 инструкции за такт. Количество L1-кэша удвоилось - теперь на команды и данные приходилось по 8 килобайт, причем кэш данных использовал более эффективную схему с обратной записью. Для эффективного предсказания переходов в циклических конструкциях применялась встроенная таблица ветвлений. В виртуальном х86 режиме, в дополнение к 4-килобайтным страницам, появилась поддержка 4-мегабайтных страниц. Регистры остались 32-разрядными, но некоторые внутренние шины расширились до 64 и даже 128 разрядов. Также 64-разрядной стала внешняя шина данных. Последний процессор этого поколения, Pentium MMX, привнес в архитектуру расширенный набор команд, позволявший эффективно оперировать с упакованными целочисленными данными, находящимися в 64-разрядных MMX регистрах. В 1995 году был представлено семейство процессоров P6, имевшее уже 3 независимых конвейера. Первым процессором этого семейства был процессор Pentium Pro. Принципиальное отличие этого семейства состоит в том, что P6 преобразует команды x86 во внутренние, RISC-подобные команды, называемые микрокомандами (micro-ops). Это позволяет устранить многие ограничения, свойственные набору команд x86, такие как нерегулярность кодирования команд, операции целочисленных пересылок регистр-память и переменная длина непосредственных операндов. Шина адреса процессоров P6 расширилась до 36 разрядов, что позволяет использовать адресное пространство размером до 64 гигабайт.
Процессор Pentium III привнес в архитектуру IA-32 расширения SSE (Streaming SIMD(Single Instruction Multiple Data) Extensions) - стали доступны новые 128 разрядные регистры и SIMD операции над упакованными операндами с плавающей запятой с одинарной точностью.
Прежде чем приступить к рассмотрению архитектуры нового процессора от Intel - Pentium 4 Willamette, и сравнить все инновации, примененные в нем, с процессорами сегодняшними, подробно рассмотрим архитектуру семейства P6 - все выпускаемые сейчас процессоры Intel принадлежат к этому же семейству. Как это работает - процессоры P6Полная обработка каждой инструкции занимает определенное количество тактов процессора. При этом возможно разделить процесс обработки на этапы, что позволит начать выполнение следующей команды сразу вслед за тем, как предыдущая команда пройдет первый этап - это, собственно, и есть принцип конвейерной обработки (pipelining), применяемый еще со времен процессоров 80486 и Pentium, в которых использовался стандартный 5-ти ступенчатый конвейер. Суперконвейеризация (superpipelining), примененная в семействе P6, делит ступени стандартного конвейера на более мелкие части. Очевидно, что с увеличением числа ступеней каждая отдельная ступень выполняет меньшую работу и, следовательно, содержит меньше аппаратной логики. Временной интервал между поступлением набора входных воздействий на входы схемы и появлением результирующих сигналов на ее выходах - задержка распространения (propagation delay), в результате, становится существенно меньше, что позволяет… Внимание !
Благодаря более коротким задержкам распространения сигнала в каждой отдельно взятой ступени конвейера становится возможным повышение тактовой частоты.
Совершенно аналогичный эффект уменьшения задержек распространения сигнала достигается с помощью перехода на более тонкий технологический процесс - например, с .18 микрон на .13. Очевидно, что архитектура семейства P6, применяемая в процессорах P3, исчерпала себя на частоте чуть более 1-го гигагерца, применительно к технологическому процессу .18 микрон.
Казалось бы, нет ничего проще - увеличивай число ступеней конвейера и поднимай частоту процессора в свое удовольствие. Но суперконвейерная архитектура имеет серьезный недостаток. При выполнении неправильно предсказанных переходов и операций необходима полная очистка конвейера, которая занимает тем больше времени, чем больше ступеней насчитывает конвейер, причем снижение производительности в некоторых случаях получается просто удручающим.
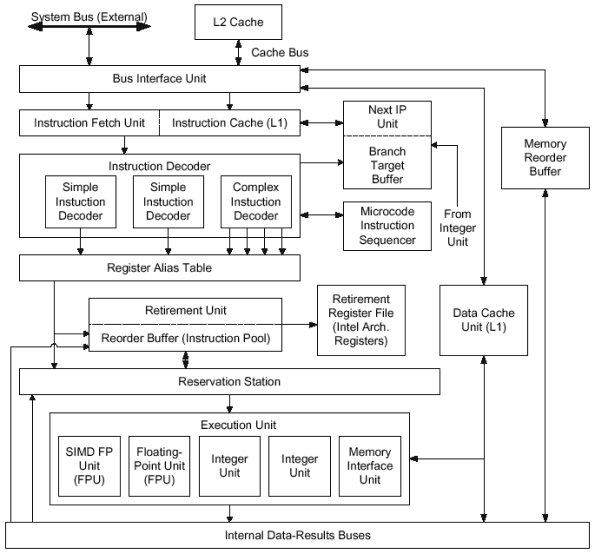 Рассмотрим поэтапную работу конвейера процессора P6, состоящего из 12 ступеней. Конвейер можно разделить на три самостоятельных функциональных блока - входной блок упорядоченной обработки (in-order front end), отвечающий за декодирование и обработку команд, ядро исполнения с изменением последовательности (out-of-order core), где, собственно, и происходит выполнение команд, и конвейер упорядоченного вывода команд из последовательности (in-order retirement). Блок выборки команды (instruction fetch unit) считывает поток инструкций из L1-кэша команд порциями по 32 байта за такт. Для поиска начала команды используется текущий указатель команды (IP-instruction pointer), а затем выровненные 16 байт команды передаются на три дешифратора. В случае, если команда находится в конце первой строки кэша, считывается вторая строка кэша для получения недостающих байт. Прежде чем перейти к рассмотрению работы дешифраторов, рассмотрим механизм предсказания переходов. Предсказание переходовУказатель команды рассчитывается блоком выборки команды на основании информации, полученной от буфера адреса перехода (BTB - branch target buffer), и основанной на битах предыстории ветвлений, которые генерируются блоком целочисленных вычислений, предназначенным для обработки микрокоманд переходов (Integer Unit), который будет подробно описан ниже. Предсказание переходов (ветвлений) призвано свести к минимуму холостую работу конвейера и обеспечить его непрерывным потоком команд. Вообще, в среднем до 10 процентов кода программы составляют безусловные переходы, передающие управление по новому указанному адресу, и от 10 до 20 процентов - условные переходы, которые меняют или не меняют ход выполнения программы в зависимости от результата сравнения или выполнения какого-либо другого условия. В случае, если условный переход не выполняется, программа просто продолжает выполнение следующей по порядку команды. Безусловные переходы проблем не вызывают, процессор точно знает, что они будут выполнены и поэтому просто начинает выборку команд по указанному адресу. Команды условных переходов представляют определенные трудности, потому что процессор не знает, будет ли выполнен переход до тех пор, пока команда не пройдет исполнительную ступень конвейера. Однако ожидание, пока команда ветвления покинет исполнительную ступень, означает временный отказ от возможности выборки и обработки дальнейших команд. Для предсказания переходов процессор использует расширенный алгоритм Yeh'а, позволяющий с большой достоверностью спрогнозировать, будет ли выполняться переход. Если предсказание окажется верным, то исполнение продолжится с малой задержкой или совсем без задержки. Если же предположение ошибочно, то частично выполненные команды придется удалять из конвейера, а новые команды выбирать из области памяти с правильным адресом, декодировать и выполнять их. Это повлечет за собой существенное снижение производительности, напрямую зависящее от глубины конвейера - для архитектуры P6 в случае ошибочного предсказания перехода потери составят от 4 до 15 тактов. Алгоритм предсказания ветвлений является динамическим двухуровневым и основывается на поведении команд перехода за предшествующий период времени (поскольку один и тот же переход часто выполняется более чем один раз, например, в цикле), а также на поведении конкретных групп команд, для которых с большой вероятностью можно предсказать конкретный переход. Точность предсказания данного алгоритма составляет порядка 90 процентов. Итак, выровненные 16-байтовые команды передаются в дешифратор команд (Instruction Decoder) , состоящий из трех параллельных дешифраторов, два из которых - простые (Simple), и один - сложный (Complex). Задача каждого дешифратора - преобразование IA инструкции в одну или несколько микрокоманд (micro-ops). Простые дешифраторы обрабатывают команды x86, транслируемые в единственную микрокоманду. Сложный дешифратор работает с командами, которым соответствуют от одной до четырех микрокоманд. Некоторые особенно сложные команды невозможно непосредственно декодировать даже сложным дешифратором, поэтому они передаются в планировщик последовательности микрокоманд (MIS - microcode instruction sequencer), генерирующий необходимое число микрокоманд. Если простой дешифратор встречает команду, которая не поддается трансляции, то она передается в сложный дешифратор, либо в планировщик последовательности микрокоманд. Такая пересылка слегка замедляет дешифрацию, но за счет буферизации с помощью станции-резервуара (Reservation Station), работу которой мы еще рассмотрим, не очень значительно сказывается на производительности. В случае, если сложные и простые команды безупречно выровнены их соответственными дешифраторами, то дешифраторы способны генерировать в общей сложности шесть микрокоманд за такт, но, как правило, из всех трех дешифраторов за один такт выдаются три микрокоманды, соответствующие, в среднем, двум - трем IA командам, которые передаются в буфер восстановления последовательности (ROB - Reorder Buffer). ROB содержит 40 элементов, размером 254 байт каждый, и может хранить микрокоманду, два связанных с ней операнда, результат и несколько битов состояния. Последним этапом перед выполнением команд является отображение регистров, осуществляемое в таблице псевдонимов регистров (RAT - register alias table). Архитектура x86 предусматривает только восемь 32-разрядных регистров общего назначения, а с таким малым числом регистров вероятность того, что две соседние команды будут использовать один регистр, относительно велика. Отображение регистров помогает ослабить влияние таких регистровых взаимозависимостей (register dependencies) - в случае необходимости записи в один и тот же регистр для двух команд их невозможно будет исполнить вне очереди без отображения регистров, так как более поздняя команда не может быть обработана до завершения более ранней команды. При отображении регистров происходит преобразование программных ссылок на архитектурные регистры в ссылки на 40 физических регистров микрокоманд, реализованных в буфере восстановления последовательности. По существу, процессор "размножает клонированием" ограниченное число программируемых, архитектурных регистров и отслеживает, какие клоны содержат наиболее поздние значения. Это предотвращает задержки, которые в противном случае были бы внесены в процесс обработки команд взаимозависимостями в результате конфликтующих обращений к регистрам. Станция-резервуар выступает диспетчером и планировщиком микрокоманд, для чего непрерывно сканирует буфер восстановления последовательности и выбирает команды, готовые к исполнению (имеющие все исходные операнды). Результат выполнения возвращается назад в буфер и сохраняется вместе с микрокомандой до вывода. Порядок исполнения команд основывается не на их первоначальной последовательности, а на факте готовности команды и ее операндов к исполнению, это и есть out-of-order - исполнение с изменением последовательности. Если дешифраторы приостановили работу, исполнительные блоки продолжают работать, пользуясь командами, поставляемыми резервуаром, а в случае занятости исполнительных устройств, резервуар предоставляет возможность дешифраторам работать. Заполняется резервуар в очень редких случаях, что приводит к приостановке работы дешифраторов. Выполнение микрокоманд осуществляется двумя целочисленными блоками, двумя блоками вычислений с плавающей точкой и одним блоком взаимодействия с памятью - таким образом, возможно выполнение до пяти микрокоманд за такт процессора. Два целочисленных блока способны исполнять две целочисленные микрооперации одновременно. Один из блоков, как упоминалось выше, разработан специально для выполнения операций перехода. Он способен обнаруживать ошибочно предсказанный переход и оповещать буфер предсказания переходов о необходимости перезапуска конвейера. Рассмотрим это подробнее. Дешифратор прикрепляет к команде перехода оба адреса - предсказанный адрес перехода и предварительно признанный неудачным. Когда целочисленный блок исполнения выполняет операцию перехода, он в состоянии определить, какая из ветвей была выбрана. В случае перехода по предсказанию все предварительно накопленные и выполненные команды данной ветви маркируются как годные для дальнейшего использования, и продолжается исполнение данной ветви программы. В противном случае, блок выполнения перехода в целочисленном блоке изменяет статус всех команд данной ветви на "подлежащие удалению". Потом передает в буфер адреса перехода правильный адрес перехода, и буфер, в свою очередь, перезапускает конвейер с этого адреса. Блок взаимодействия с памятью отвечает за выполнение микрокоманд загрузки и сохранения. Загрузка требует только указания адреса памяти, поэтому может быть представлена одной микрокомандой. Сохранение требует также указания содержимого для сохранения, поэтому кодируется двумя микрокомандами. Часть блока, обрабатывающая команды сохранения, имеет два порта, что позволяет обрабатывать адресную и микрокоманду данных параллельно. Также возможно параллельное выполнение операций загрузки и сохранения в одном такте. Для операций с плавающей точкой предусмотрены два блока вычислений, причем второй предназначен для обработки SIMD инструкций. Команды, которые исполняются не в той последовательности, которая предписана программой (speculative), следует в конечном итоге расположить в должной последовательности - иначе процессор не всегда сможет получить правильные результаты. Буфер восстановления последовательности сохраняет статус исполнения и результаты каждой микрокоманды. Микрокоманда выводится блоком вывода, который, подобно станции-резервуару, сканирует буфер восстановления последовательности на предмет обнаружения микрокоманд, которые уже не повлияют на выполнение других микрокоманд. Такие команды признаются завершенными, и блок вывода выстраивает их в первоначальную последовательность, учитывая прерывания, исключения, точки останова и неверные предсказания переходов. Блок вывода способен выводить три микрокоманды за такт. При выводе микрокоманды результаты записываются в выводящий регистровый файл (RRF - retire register file) и/или память. Выводящий регистровый файл содержит 8 регистров общего назначения и 8 регистров для данных с плавающей точкой. После того, как микрокоманда выведена, она удаляется из буфера восстановления последовательности. Операции записи в память откладываются до той поры, пока вызвавшая их микрокоманда не будет выведена. Для этого в P6 предусмотрен буфер упорядочения обращений к памяти (MOB - memory order buffer), в котором по командам, выдаваемым блоком записи в память, сохраняется информация о данных и адресах. Буфер упорядочения обращений к памяти пересылает данные в память только после того, как буфер восстановления последовательности уведомит его о том, что микрокоманда, произведшая запись в память, удаляется. Итак, мы рассмотрели основные принципы работы и устройство процессоров семейства P6. Посмотрим, насколько же будет отличаться спроектированный с чистого листа Willamette - Pentium4, тактовые частоты которого начинаются с 1.4 гигагерца, действительно ли это прорыв в будущее, или лишь способ увеличить предельную тактовую частоту кристалла в рамках имеющегося технологического процесса .18 микрон.
Ответы на этот и многие другие вопросы читайте в следующей части нашего обзора…
Александр Полувялов ([email protected] )
Опубликовано -- 13 ноября 2000 г. |
| Процессоры | Системные платы | Видеосистема |
Copyright (c) by iXBT, 1997-2001. Produced by iXBT Дизайн (с) 1998 студия РусАрт |