
| Процессоры | Системные платы | Видеосистема |
| Процессоры | Системные платы | Видеосистема |
Willamette - как будет работать новоиспеченный флагман от Intel…
Пришло время рассмотреть подробнее новейший процессор Pentium 4 от компании Intel. Итак, мы уже знаем, что послужило причиной появления спроектированного с чистого листа Willamette - это ничто иное, как ограничения, накладываемые на тактовую частоту процессоров семейства P6 - из-за конвейера длиной 12 ступеней, причем ступеней относительно больших, которые при технологическом процессе .18 микрон, которым располагает Intel, не в состоянии работать на частотах, существенно превышающих 1 гигагерц. Предел данного технологического процесса находится где-то в районе 1.1 - 1.2 ГГц - именно поэтому, из-за недостаточной стабильности работы в предельных режимах, и был отозван опрометчиво выброшенный на рынок Pentium III Coppermine 1,13 ГГц. Естественно, предполагая такую ситуацию еще задолго до того, как она сложилась, компания Intel приняла решение о проектировании принципиально нового процессора с гиперконвейеризацией (hyperpipelining) - с конвейером, состоящим из 20 ступеней. Согласно заявлениям Intel, процессоры, основанные на данной технологии, позволяют добиться увеличения частоты примерно на 40 процентов относительно семейства P6 при одинаковом технологическом процессе. Соответственно, для технологии производства .18 микрон предел частоты составляет примерно 1,55 - 1,7 ГГц - вполне конкурентноспособный ход для обеспечения достойного отпора компании AMD, продолжающей наращивать тактовые частоты своих медных Thunderbird'ов. И это только до полноценного запуска в производство технологии .13 микрон, где для архитектуры Pentium 4 в плане повышения частот открываются более чем радужные перспективы. Однако, не все так замечательно. Как уже упоминалось, задача конвейера - обеспечивать непрерывную обработку потока микрокоманд без каких бы то ни было задержек. Для обеспечения безостановочной работы столь длинного конвейера и были применены те множественные ухищрения, позволяющие говорить о Willamette, как о принципиально новом процессоре в программе Intel. Посмотрим, что же такого интересного находится в кристалле у Pentium 4, и на какие вершины производительности позволит подняться такое кардинальное увеличение частоты. При этом надо отдать должное компании Intel - она объективно оценивает недостатки столь длинного конвейера и понимает, к чему это приводит. Вот каково мнение Intel на этот счет. Intel: "Приложения можно разделить на две основные категории - целочисленные/офисные приложения и мультимедиа приложения, использующие вычисления с плавающей точкой". Код офисных приложений содержит множество переходов, весьма трудных для предсказания, в результате чего процессор вынужден выполнять горы ненужной работы, периодически ошибаясь в предсказании ветвлений и тратя время на наполнение конвейера правильными командами. Проще говоря, для этих приложений положительный фактор увеличения тактовой частоты нивелируется увеличением количества ступеней конвейера, а иногда и вовсе выражается в падении производительности. Даже сам Intel констатирует, что в таких приложениях падение производительности из-за растянутого конвейера достигает 10-20 процентов против архитектуры P6 при равных частотах. Но унывать не стоит - Intel: "в приложениях типа текстовых процессоров уровень производительности процессора не привносит существенной прибавки в темп работы, так как его производительность несоизмеримо больше, чем "производительность" человека при чтении или письме". В общем, конечно, все верно, но звоночек тревожный… Что касается приложений, активно использующих вычисления с плавающей точкой, то тут полнейшая идиллия - из-за небольшого количества переходов и более простого их предсказания - Intel: "такие приложения не страдают от увеличения глубины конвейера, но зато существенно ускоряются благодаря увеличению тактовой частоты". При этом действительно никто не будет спорить, что максимальная производительность при исполнении таких приложений, как, например, кодировании MP3, намного более существенно облегчает жизнь пользователя, нежели непревзойденная производительность в том же Word'е. В результате Pentium 4 позиционируется не как универсальный процессор, одинаково хорошо справляющийся с любыми задачами, а как мощнейший процессор именно для современных задач с минимальным количеством ветвлений, среди которых основное место занимают приложения, непосредственно связанные c Internet - даже архитектура, на которой основан процессор, носит громкое имя NetBurst. Архитектура NetBurst - ключевые моментыВ основу микроархитектуры NetBurst от Intel вошли все перспективные наработки, применявшееся ранее в архитектуре процессоров семейства P6, но и инноваций тоже предостаточно. Минимизация влияния ошибочно предсказанных переходовЕдинственной возможностью обеспечить гиперконвейерную архитектуру непрерывной работой является выполнение команд с изменением последовательности выполнения (out-of-order execution) и выполнение команд, находящихся после команды перехода до получения реального адреса перехода, т.е. по предположению (speculative execution). При такой схеме работы процессор использует внутренний алгоритм предсказания переходов, который, естественно, не всегда точно предсказывает ветвь, по которой пойдет работа программы. Более того, чем длиннее конвейер, тем более долгое время займет его очистка и перезапуск по правильной ветви программы. Вот какие решения были применены для оптимизации данной схемы. Для минимизации неправильных переходов в процессоре Willamette применен большой, объемом 4 Кбайта (у P6 - 512 байт), буфер адреса перехода (BTB - branch target buffer), который хранит более подробную историю предыдущих переходов, нежели P6. Также применен еще более продвинутый алгоритм предсказания переходов, позволяющий с большей степенью точности предсказывать правильность переходов. Данные меры позволили добиться существенного увеличения точности по сравнению с семейством Р6 - приблизительно на треть, таким образом, для процессора Pentium 4 вероятность удачного предсказания составляет порядка 93-94 процентов. Для обеспечения блока выполнения микрокомандами, станцию-резервуар (Reservation Station), называемую в новом процессоре окном команд (Instruction Window), но не меняющей от этого своей сути и назначения, сделали значительно больше, расширив до 126 инструкций - теперь у процессора есть значительно большая свобода в выборе микрокоманд для внеочередного исполнения. Два вышеописанных нововведения являются частью Advanced Dynamic Execution Engine - усовершенствованного механизма динамического исполнения. Для обеспечения увеличенного потока микрокоманд и быстрого восстановления конвейера в случае выбора неправильной ветви программы служит Execution Trace Cache - трассирующий кэш команд. Это принципиально новый подход к организации кэша команд первого уровня - кэш находится после дешифраторов и содержит микрокоманды, готовые к исполнению, благодаря чему исключается простой конвейера, вызванный долгой дешифрацией сложных команд. При этом микрокоманды в кэше упорядочиваются в соответствии с несколькими предсказанными ветвями программы, т.е. подряд кэшируется весьма длинный кусок программы - так называемая трасса. Проще говоря, при выполнении заранее упорядоченные в кэше микрокоманды - трассы выбираются подряд, независимо от своих адресов. Благодаря этому обеспечивается увеличенный поток микрокоманд и оптимальное использование пространства кэша, вмещающего около 12 тысяч микрокоманд. А где же быстрое восстановление конвейера? Читаем дальше, скоро все будет… Уменьшение количества команд, необходимых для выполнения задачиВ примитиве это выглядит так. Множество программ постоянно выполняет повторяющиеся операции над большими объемами данных, а эти данные чаще всего представляют собой небольшие величины (значения), которые можно представить набором из нескольких бит. В результате очевидно стремление представить эти наборы данных максимально компактно и разработать операции, умеющие общаться с такими наборами данных. Эти операции называются SIMD (Single Instruction, Multiple Data) - одна команда, много данных, и призваны сократить среднее количество команд, необходимых в ходе выполнения программы. В процессоре Willamette нашло применение второе поколение команд, относящихся к расширенному набору - SSE2 (Streaming SIMD Extensions 2) - потоковые SIMD-расширения, включающие 144 новые инструкции. Их мы рассмотрим подробнее далее. Еще кое-что…В процессоре Willamette ALU (Arithmetic Logic Unit) - арифметико-логические блоки (устройства) - работают на удвоенной частоте процессора, например, у процессора с частотой 1,4 ГГц АЛУ будет работать на частоте 2,8 ГГц, т.е. выполнение операции занимает не полный такт, а половину. Блоки, выделенные золотым цветом, работают на удвоенной частоте. 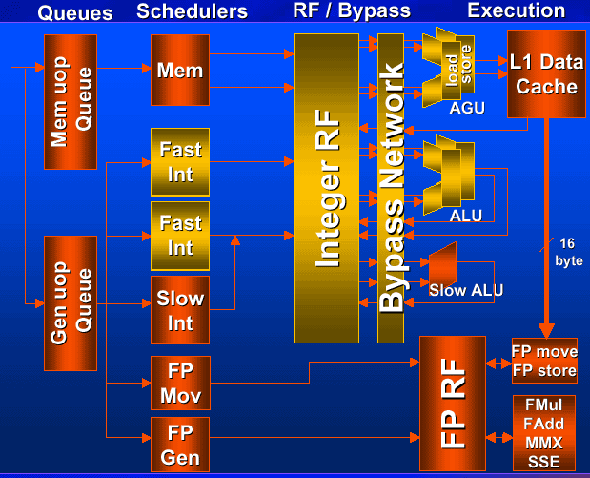
Применена потрясающая Quad-pumped 400 МГц системная шина, обеспечивающая пропускную способность в 3,2 ГБайта в секунду против 133 МГц шины с пропускной способностью 1,06 ГБайт у Pentium III. Advanced Transfer Cache 2-го уровня имеет размер 256 Кбайт и также, как и у Coppermine, имеет 256-разрядную шину, работает на частоте процессора и благодаря более высокой тактовой частоте обеспечивает большую пропускную способность. И о чем говорить не принято…Что касается быстрого восстановления конвейера. Тут все не совсем гладко. Упор делается на то, что блок дешифраторов работает как бы "отдельно" и в основной конвейер не входит, и за счет этого достигается более быстрое восстановление конвейера после неправильно предсказанного перехода. Ну, так конвейер-то от этого меньше не становится - как было 20 ступеней, так и осталось.… И кэш данных первого уровня - всего 8 Кбайт. Пока нет времени, чтобы искать объяснение, что же подвигло создателей процессора на его уменьшение относительно Coppermine. Как это работает - процессор Willamette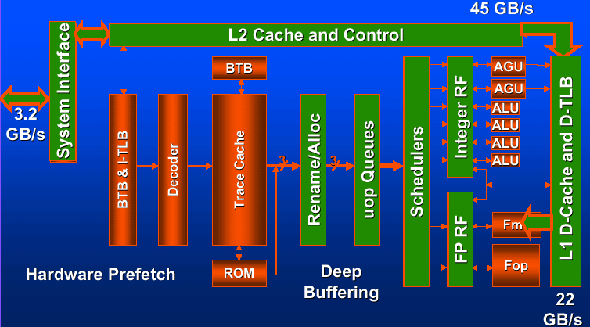
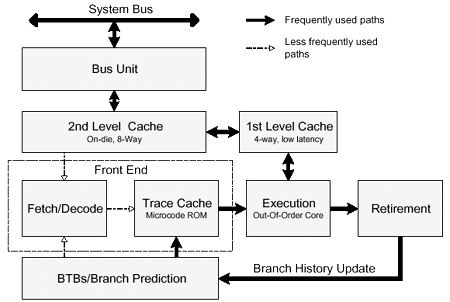
Здесь представлены две схемы процессора Willamette, в какой-то степени дополняющие друг друга для получения полноты картины. По аналогии с семейством P6, конвейер делится на три самостоятельных функциональных блока - входной блок упорядоченной обработки (in-order front end), отвечающий за декодирование и обработку команд, ядро исполнения с изменением последовательности (out-of-order core), где, собственно, и происходит выполнение команд, и конвейер упорядоченного вывода команд из последовательности (in-order retirement). Вот схема конвейера, состоящего из 20 ступеней: 
Так называемый механизм преобразования (translation engine) , он же блок выборки и дешифрации, используя буфер адреса перехода (BTB), выбирает и дешифрует команды в микрокоманды, и на основании механизма предсказания ветвлений составляет из них трассы, которые помещаются в трассирующий кэш команд. Как только трасса построена, трассирующий кэш просматривается на наличие микрокоманды, следующей за данной трассой - если она есть в кэше, то дальнейшим источником микрокоманд становится не иерархия памяти, а трассирующий кэш. Трассирующий кэш и механизм преобразования используют один и тот же механизм предсказания переходов, если требуемая микрокоманда находится в кэше, то она выбирается оттуда, если нет - берется из иерархии памяти и на ее основе механизмом преобразования формируется трасса в трассирующем кэше. С помощью буфера адреса перехода определяется адрес, указывающий местоположение следующей микрокоманды в трассирующем кэше (TC Nxt IP). Затем происходит выборка микрокоманд из трассирующего кэша (TC Fetch) и передача (Drive) в распределитель/таблицу псевдонимов регистров (RAT - register alias table). Распределяются ресурсы, необходимые для выполнения - буферы загрузки, буферы сохранения и т.д. (Alloc) и осуществляется отображение логических регистров на физическое регистровое пространство (Rename). Микрооперации помещаются в очередь (Queue), где содержатся до тех пор, пока не появится место в планировщиках (Schedulers). В планировщиках выполняется разрешение взаимозависимостей (dependencies) микрокоманд, которые затем передаются в регистровые файлы (register files) соответствующих блоков выполнения (Dispatch). Происходит выполнение микрокоманды (Execute), а также вычисление флагов (Flags). При исполнении команды перехода происходит сравнение реального адреса перехода и предсказанного (Branch Check) и передача нового адреса в буфер адреса перехода (Drive). Что же мы видим! В конвейер, состоящий из 20 ступеней, не вошли ни механизм преобразования (блок выборки и дешифрации), осуществляющий выборку и дешифрацию команд, ни блок вывода, подробно описанный в первой части. Хотя совершенно очевидно, что в процессоре они есть, и если первый еще можно предположительно отделить от конвейера за счет громадного буфера в лице трассирующего кэша, то блок вывода уж точно никуда не денешь… Что же получается - ступеней вовсе не 20, а больше! 22? 25? Или все 30? Ждать правды осталось недолго… Инструкции Streaming SIMD Extensions 2Важнейшим положительным нововведением нового процессора, которое действительно сможет поднять его над конкурентами, является использование второго поколения потоковых команд-расширений - SSE2 (Streaming SIMD Extensions 2). Новый набор команд поддерживает новые форматы упакованных данных и увеличивает производительность при целочисленных SIMD операциях при использовании 128-разрядных регистров. Введены новые упакованные типы данных - с плавающей точкой с двойной точностью и несколько целочисленных 128-битных типов. Все новые типы данных позволяют производить действия с ними в XMM-регистрах. Также усовершенствования коснулись 68 целочисленных SIMD инструкций, которые работали в процессорах Pentium II и Pentium III c 64-разрядными MMX-регистрами, в архитектуре Willamette поддерживают и работу c XMM-регистрами. Данное нововведение позволит разработчикам иметь большую гибкость при написании SIMD-кода, используя как MMX, так и XMM-регистры. Очевидно, что данные усовершенствования позволят серьезно поднять производительность в таких приложениях, как кодирование/декодирование звука и видео, распознавание речи, а также получить определенный прирост в 3D-графике, научных и инженерных задачах благодаря двойной точности вычислений с плавающей точкой. В дополнение к основным SIMD командам введено несколько новых инструкций, позволяющих программистам управлять кэшированием данных. Возможна предварительная выборка данных до того, как ими действительно надо будет пользоваться, и потоковая передача данных из/в регистры, не разрушая содержимое кэшей. При этом инструкции SSE2 полностью основываются на SSE, не требуют поддержки операционной системой и, скорее всего, окажутся самым главным козырем процессора Willamette в борьбе за вершины производительности.
Итак, собранная по крупицам информация о новом процессоре уже позволяет составить определенное впечатление о новом процессоре Willamette, и определить его слабые и сильные стороны. При написании обзора не использовалось каких-либо утечек информации о новом процессоре, которая держится в строжайшем секрете, вся информация извлекалась из документации, пресс-релизов и презентаций, причем часто противоречащих друг другу, автором которых является сама компания Intel. А нашей задачей было извлечь истину, постараться систематизировать материал и изложить его в доступной для читателя форме. Однако остались определенные пробелы, которые мы постараемся ликвидировать по мере поступления информации, скорее всего, это произойдет уже после официального объявления процессора 20 ноября. А как раз к выходу процессора ждите появления заключительной части затянувшегося повествования, в которой будет самое интересное - тесты и фото- галерея настоящего компьютера на Pentium 4 Willamette - бог ты мой, какой у него радиатор… |
|
Александр Полувялов ([email protected] )
Опубликовано -- 17 ноября 2000 г. |
| Процессоры | Системные платы | Видеосистема |
Copyright (c) by iXBT, 1997-2001. Produced by iXBT Дизайн (с) 1998 студия РусАрт |